
Optionale Tags (html)
Websites schlank zu halten, es ist in vielerlei Hinsicht sinnvoll. Der Quelltext kann schlank sein, die HyperText Markup Language (HTML) … das Design kann schlank sein … Scripte und Cascading-Style-Sheets (CSS) sowie das Laden externer Inhalte, seien es Bilder, Videos, Schriften, es kann schlank gehalten sein.
Allein der „Content“, der Inhalt einer Website darf, kann, sollte fett sein – und der Inhalt einer jeden Website steht im Quelltext:
Via Scripte generierte Websites sind keine World-Wide-Web-Sites!
Wird der Quelltext verborgen, bemüht versteckt, unleserlich gemacht, steht dies wider einer kulturell-geistigen Entwicklung des Netzes.
Der Mensch braucht den Zugang zu Quelltexten – das WWW lebt von diesem Kontext, ungeachtet aller Kommerzialisierung, denn das WWW ist am Ende von freien Menschen für Menschen gemacht.
Für wen oder was denn sonst!
Quelltexte lesen zu lernen, es ist ein guter Weg, das WWW verstehen zu lernen.
Das WWW ist zugleich eine der größten Quellen Klima schädigender Emissionen.
Hält man das WWW sparsam, kommt es allen Menschen entgegen. Der ökologische Fußabdruck des WWW im Denken eines minimalen Verbrauchs von Ressourcen – für einen maximierten Nutzen. Es kommt uns zugute.
Hält man es sparsam, kommt es auch dem Verstehen des Menschen entgegen – denn vieles lässt sich (frei nach Wittgenstein) einfach sagen, schreiben, darstellen; und dies ist immer schon zugänglicher als das Verklausulierte, komplex Gemachte … als alles Aufgebauschte.
Das Schreiben von optionalen Tags ist optional.
Diese Tautologie enthält die Frage, wann dieses Optionale zweckdienlich gespart, also nicht geschrieben werden kann – und wann besser dann doch.
Grundsätzlich erscheint mir die Beantwortung dieser Frage darin zu liegen, ob das Weglassen oder das Schreiben des Optionalen dem Menschen nun besser dient oder nicht.
HTML bietet die Grundstruktur der Semantik im Web. Diese Sprache ist das Werkzeug aller Quelltexte – der Boden für das Leben im WWW.
Hier sollten „Sparmaßnahmen“ behutsam und mit Bedacht erfolgen – wenn diese Sprache html nicht besser ganz ausgelassen wird von dem Vorhaben, das WorldWideWeb (WWW) schlank, effizienter … klimaneutral machen zu wollen.
Jens Meiert – „alles“ schlank machen?
Jens Meiert zeigt auf seiner Website schlank gemachtes HTML – und man kann entsprechend sehen, wie der Quelltext dann ausschaut.
Die Für und Wider einer schlanken HTML stellt er unter HTML und Performance
weiter zur Diskussion – mit dem Ergebnis, kein optionales HTML
mehr auszuliefern.
Verkürzt ist die Quintessenz bei Meiert: alles weglassen im Quelltext rund um HTML, was optional ist.
Der Gewinn, derart schlankes html umzusetzen, sei neben der noch zu ermittelnden Einsparungen im Datenfluss gar auch ein leichter lesbarer Quelltext für den Menschen.
Beides sei dahingestellt.
Was alles optional in der HTML ist, mag man beim World Wide Web Consortium (W3C) oder bei Meiert erkunden – oder bei SELFHTML oder anderswo: Es ist recht umfangreich und thematisch vielfältig, was so alles als Option für das Schreiben von Quelltexten angeführt und aufgezählt wird.
Quelltexte im Vergleich
Zeige natürlich nur Auszüge – und verweise auf die jeweilige Website.
Auszug meines eigenen Quelltextes spare ich mir hier – da schauen Sie bei Wunsch direkt selbst nach.[*]
[*] Wer nicht weiß, wie das geht, schaue bitte unter Seitenquelltext aufrufen nach [Seite: „Tastenkürzel (shortcuts) beim Editor Bluefish“, Sprung zum Absatz].
Im Vergleich ein Auszug des Quelltextes der oben verlinkten Website von Jens Meiert – alle optionalen Tags werden nicht ausgeliefert (wenngleich vom Browser ergänzt); hier im Kern bei p und li:
Überspringen
<h3 id="toc-quotes">Optionale Anführungszeichen</h3>
<p>Attributswerte müssen nicht immer in Anführungszeichen gesetzt werden (unerheblich ob einfache oder doppelte Anführungszeichen). Die HTML-Spezifikation erläutert detailliert, wie das Parsen von Attributen funktioniert, und entsprechend skizziert dieser Abschnitt eher, wann Anführungszeichen ausgelassen werden können, und wann nicht.
<pre><code><!-- mit Anführungszeichen -->
<link rel="stylesheet" href="default.css">
<!-- ohne Anführungszeichen -->
<link rel=stylesheet href=default.css></code></pre>
<p>Solange nach dem Gleichheitszeichen oder als Teil des Attributswertes
<ul>
<li>kein einfaches oder doppeltes Anführungszeichen (offensichtlich, da wir von der Syntax ohne Anführungszeichen sprechen) oder Gravis (»`«),
<li>kein Gleichheitszeichen (»=«),
<li>kein Größer-als- (»>«) oder Kleiner-als-Zeichen (»<«),
<li>kein Und-Zeichen,
<li>kein Leerzeichen oder Zeilenumbruch,
<li>kein Nullzeichen (U+0000) und
<li>kein Dateiende
</ul>
<p>folgt, muss der entsprechende Attributswert nicht in Anführungszeichen gesetzt werden.
<p>Normalerweise beendet ein Leerzeichen dann die Zeichenfolge, um zum nächsten Attribut zu führen, oder ein Größer-als-Zeichen, das bedeutet, dass das Start-Tag vollständig ist.
<p>Gibt es einen einfacheren Weg, all diese Zeichen zu verinnerlichen? Aus meiner Erfahrung mit dem manuellen Auslassen optionalen Codes (und dem Gebrauch korrekter Zeichensetzung, was bei Anführungszeichen relevant ist), ja. Die Daumenregel, die ich verwende, besteht darin, zu schauen, ob ein Attributswert Gleichheits- oder Leerzeichen beinhaltet – wenn nicht, können die Anführungszeichen meistens ausgelassen werden.
Bei Zeilenumbruch wird es für meinen Geschmack sehr unleserlich – probieren Sie es selbst aus.
Für den dritten Vergleich eine der zahlreichen Websites, deren Seitenmacher offenbar noch nie etwas von einem Quell-Text gehört haben, eingepackt in ein Details-Element.
Content
im Kuddelmuddel-Design
Quelltext – Speckmann Webdesign: Die Zukunft des Webdesigns (…)
?

Quelltext – Speckmann Webdesign
Den „Content“ finden Sie in Zeile 259 (Bild 5).
Zeile 1 bis 52 – Scripte, kommentierte Style-Angaben:

Zeile 53 bis 105 – Style und Media Queries:

Zeile 106 bis 158 – Media Queries, Style (samt important!
):

Zeile 159 bis 210 – wie zuvor:

Zeile 211 bis 261 – Scripte, sodann „Content“ in Zeile 259:

Zeile 262 bis 314 – SVG, Scripte:
Zeile 315 bis 334 – Script:
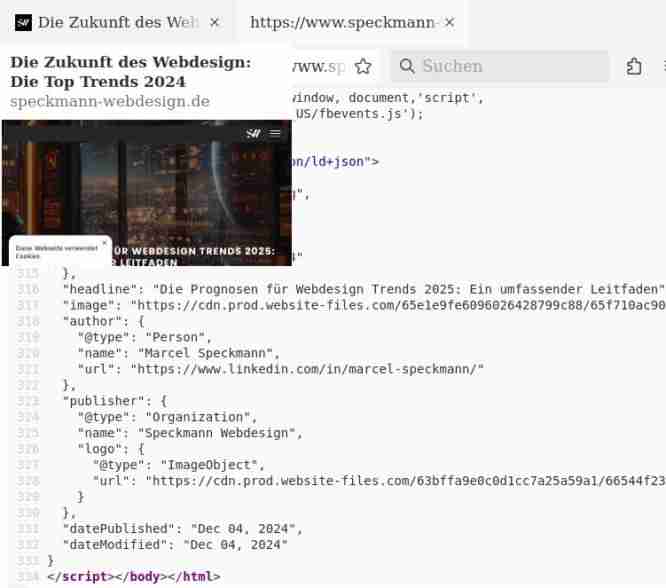
Speckmann Webdesign – könnte es sein, dass selbst der klügste Mensch als Kunde solchen Agenturen auf Gedeih und Verderb ausgeliefert ist?
Denke, hier könnte der Webdesigner „sparen“ …
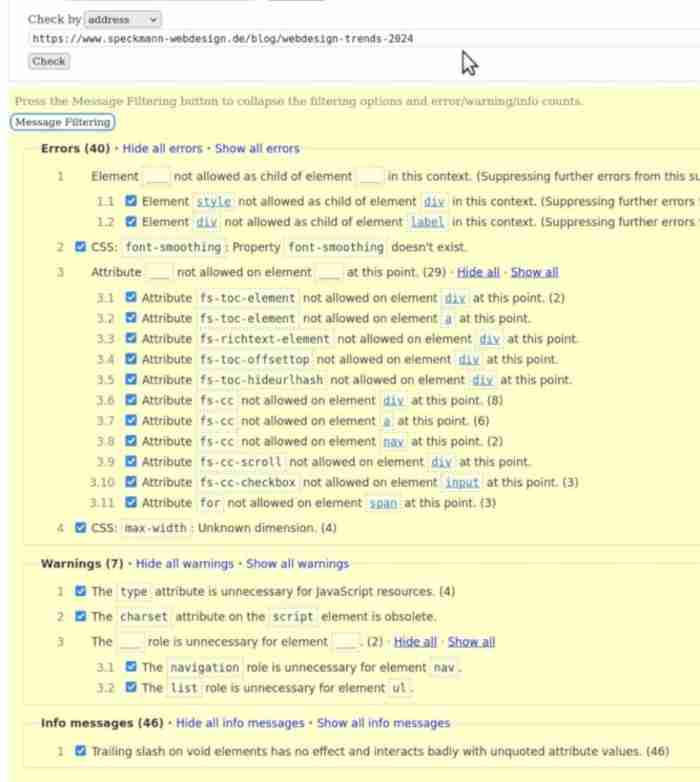
Ergebnisse Validatoren (W3C)
HTML – Errors (40), Warnings (7), Info messages (46)
:
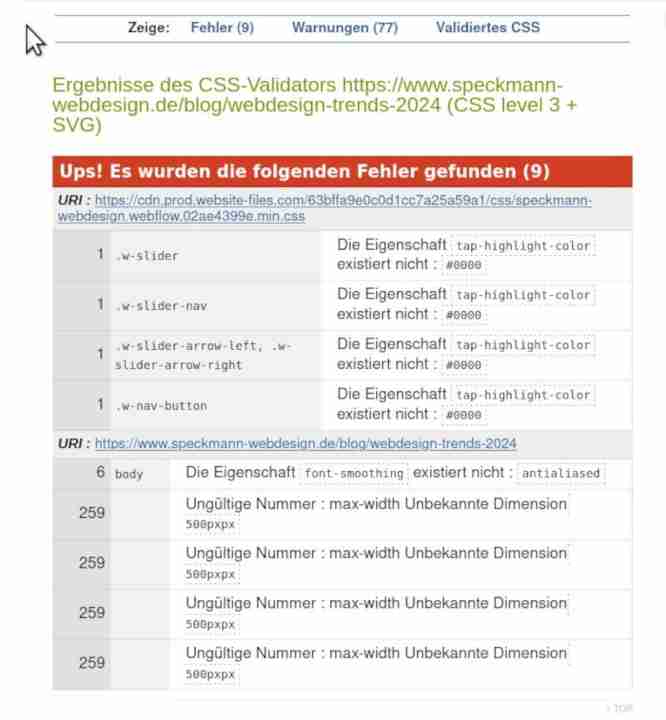
CSS – Fehler (9), Warnungen (77)
:
[Ende Details-Element]
„Quelltext“ – „Content“ – Design?
Eine unzumutbare Ansammlung von (internen) Styles, Scripten, DIV-Suppen … von Cookie-, Tracking-, Targeting-Techniken … exemplarisch.
Wird hier auf „wohl geformt und validiert“ gepfiffen?
Wo ist der Text, der Inhalt, dieses Content first
in diesem Kuddelmuddel? Wer kann das noch lesen? Wenn man es kann: Wer will derlei „lesen“?
Scott schafft das vielleicht noch, diesen Wahnsinn wieder zugänglich, lesbar zu machen … für alle Menschen … und am Ende des Tages wohl auch wieder für die Schreiber solcher Seiten.
Die Validatoren spucken mitunter für derlei Websites mehr error, warning, info
aus als die Website insgesamt Text enthält.
Schade vielleicht, dass die Intoleranz der XHTML / XML sich nicht durchsetzte?
Das Netz samt dem Feld „Professioneller Webdesign-Agenturen“ wäre wohl überschaubarer … oder in wohl geformter Hinsicht ehrgeiziger …
Heutzutage, so lehren meine Durchsichten, schludern die „Professionellen“ des Web schlimmer, als es ein Amateur je hinbekäme …
Es ist ja auch gut, dass die Toleranz nicht nur der Browser so manches Abenteuer glattbügelt.
Gegen „kaputte“, wenig glücklich „gebaute“ Websites habe ich nichts, wenn da was drin steht, also Content, irgendein brauchbarer Inhalt.
Da wackelt das Häuschen halt ein büschen … aber das Netz ist und bleibt zugänglich für diejenigen, die etwas zu sagen haben, aber weder Geld für eine Professionelle Webdesign-Agentur
aufbringen können / es (gut begründbar) nicht wollen,
noch den mitunter angestrengt wirkenden Ehrgeiz haben, zu dieser Liga Gratulation, keine Fehler gefunden
im ersten Website-Entwurf aufsteigen zu müssen.
SELFHTML – die Dinge lassen, wenn sie helfen?
Optionale Tags bei SELFHTML.
Beim Parsen fügt der Browser also hinzu, was der eine Mensch beim Schreiben seines Quelltextes weglässt.
Browser ersetzen so manches, was der sparende wie der unbedarfte Mensch so alles weglassen könnte – etwa den body oder gar das html-Element.
Die Gründe sind ebenda und hier im Text skizziert, etwa hinsichtlich der Übereinstimmung dessen, was der Browser zeigt mit dem, was der Mensch geschrieben hat; dies entspricht einem Vorbeugen von Missverständnissen bei der Interpretation von Quelltexten – sei es auf der Ebene der Technik, sei es auf der Ebene des Lesens von Quelltexten durch andere Menschen.
Das Webentwickler seit Anbeginn des Schreibens von Websites gelernt haben, optionale Tags auch zu schreiben, mag inhaltlich nicht relevant sein, also diese erlernte „Gewohnheit“ sei nicht unbedingt relevant, jedoch mag hierin der Gedanke liegen, dass die Option des Weglassens zwar verfügbar ist, jedoch nicht Freunde der Umsetzung findet. Und dieses Auslassen von Optionalem hier und da schlicht „verboten“ respektive „falsch“ bleibt – wie etwa bei der vorzüglichen XHTML 1.0 Strict.
Das Google für ein Weglassen aller Optionen plädiert, sei kein Grund, es zu tun.
Diese Sparsamkeit des Konzerns hat möglicherweise eine andere Motivation als ein möglicherweise ja leichteres Lesen und besseres Verstehen von Quelltexten.
Schnellere Seiten – wodurch auch immer – sind durchaus dem Erfolg Googles förderlich. Aber hier müssen die Nutzer und Macher ja nicht unbedingt ohne weitere Fragen zu stellen mitgehen …
Das Netz war noch nie so schnell wie in unseren Tagen obgleich es Tag für Tag wächst, obgleich das Datenvolumen der einzelnen Seiten bis ins Maßlose angestiegen zu sein scheint, als dass Tausende CSS spärliche Inhalte / Texte schmücken, unzählige Scripte angeblich Nutzererlebnisse verbessern, ungeahnte Mengen von Informationen über die Nutzer des Netzes generiert werden – auch von Herrn Meiert. Was der Mann wohl mit diesen Daten macht?
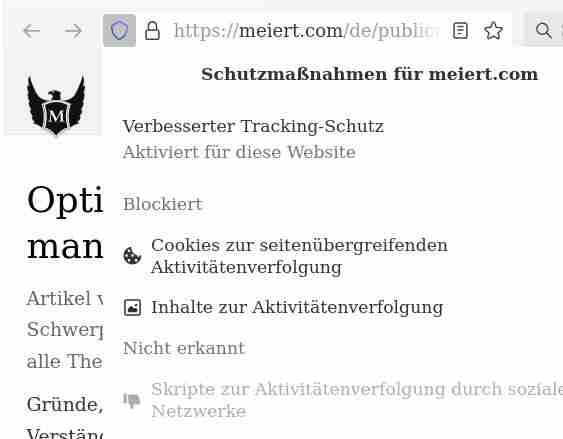
Hier „spart“ der Mensch mal lieber nicht?
Die gedachten „Einsparungen“ an der HTML sollten für jede Vergleichbarkeit zahlenmäßig besser eruiert werden – um im Verhältnis der Aufgaben dieser Sprache zu dem, was an anderen Stellen an Potential von Einsparungen zu holen sein könnte, gebracht werden zu können.
Möglicherweise entpuppt sich der Wille, HTML zu verschlanken, als Weg in die falsche Richtung … während hinter diesen bemühten Rücken mancher fein-geistiger Philosophen und Theoretiker die Welt der Akrobaten und Gaukler, der Maßlosen und Nimmersatten, der Verschwender und Ignoranten sich die Bäuche vor Lachen halten.
Die Logik des Satzschlusspunktes und des Absatzes
Lernen von geschriebenen Sätzen.
Der Satzschlusspunkt beendet als Zeichen einen Satz – mehr oder weniger gut erkennbar durch den „Punkt“ – und das folgende Sätze mit einem Großbuchstaben den Text fortsetzen, selbst wenn das erste Wort in diesem neuen Satz im Fließtext klein geschrieben gehört.
Nun könnte eine Einsparung des Satzschlusspunktes erfolgen – keine große Einsparung, jedoch eine Einsparung. Eine Einsparung eines als Option denkbaren Zeichens.
Endet ein Absatz, so die denkbare Regel, kann der Satzschlusspunkt weggelassen werden. Denn der folgende Absatz markiere ja ausreichend den Beginn eines neuen Satzes(.)
Bei Ende des gesamten Textes mag man wieder diskutieren, ob dann nicht doch wieder der Satzschlusspunkt obligatorisch gesetzt gehört … da wüsste man beim Lesen des letzten Satzes im letzten Absatz, das bei einem „Punkt“ in diesem Satz auch das Ende des Textes erreicht ist … (was für Überlegungen!).
Ob alles in Kleinschrift zu verfassen sparsam sei oder schlicht eine Verfälschung mitbringt, Missverständnisse des Inhaltes erzeugt, diese Gedanken sind in der ewigen Diskussion, die Dinge einfach und noch einfacher machen zu wollen – für ein möglicherweise nur vermeintlich besseres Verstehen, für einen vermeintlich besseren Zugang und einer möglicherweise nur vermeintlich besseren Handhabung.
Lasse ich allein die verbotenen
Tags in HTML5 weg – die in XHTML 1.0 Strict (EXtensible HyperText Markup Language) bis heute obligatorisch sind – zeigt sich eine gewisse Einsparung im Quelltext:
Meiert geht aber einen Schritt weiter und rät, (in HTML5) auch die derzeit noch optionalen Tags ebenfalls auszusparen, sie nicht mehr zu schreiben.
Eine Kompatibilität zu XHTML 1.0 Strict wäre dann gar nicht mehr gegeben.
Dies erscheint mir wie das obige Weglassen des Satzschlusspunktes … man kann es so denken … man könnte es so machen …. Aber hilft es wirklich beim Lesen von Quelltexten? Für ein besseres Verstehen von Quelltexten, wenn man weglässt, was die Browser ohnehin (und die Menschen in Gedanken) dann wieder hinzufügen?
Die Inkonsistenz des Erscheinungsbildes des „sparsamen Quelltextes“ im Sinne Meiert zu dem, was der Browser uns (etwa im „Inspektor“) zeigt, erscheint mir eher ein Bruch für jedes Verstehen zu enthalten.
Der Satzschlusspunkt zeigt das Ende eines Satzes. Punkt.
Das Verschachteln von Listen erscheint mir nebenbei übersichtlicher wie auch das Erkennen von Absätzen, wenn der Mensch die jeweiligen Enden als Zeichen deutlich mitgeteilt bekommt – in Fließtexten wie in Quelltexten.
Für die Validierung ist es derzeit unerheblich, ob optionale Tags geschrieben werden oder nicht – selbst die „verbotenen“ Tags entlocken dem Validator schlimmstenfalls eine Info
, dass diese Zeichen (in HTML5) überflüssig seien …
Diese „Optionen“ bieten schon ein etwas chaotisch anmutendes Feld freier Beliebigkeit: der eine setzt, was der andere weg lässt – und beide können dieses wie jenes tun, schreiben und weglassen, ohne Folgen befürchten zu müssen.[*]
[*] XHTML 1.0 Strict ist hier klarer, diese eindeutige Sprache machte mir damals das Erlernen des Schreibens einer Website leichter als die „toleranten“ Alternativen.
Der Quelltext bei Meiert liest sich entsprechend anders als etwa mein eigener Quelltext. An beide Lesarten mag man sich gewöhnen. Nur, die aufgeführten Vorteile des Weglassens von „Satzschlusspunkten“ – um es pointiert zu formulieren – erschließt sich weder meinem Auge noch meinem Verstehen bei der Lektüre von Quelltexten – und das Erlernen dieser Sprache wird wohl nicht leichter, wenn der Anfang eines Tags zwar gesetzt werden muss, sein Ende indessen – bei einigen – nur zu denken sei.
Die vermuteten Einsparungen im Datenfluss durch das Weglassen optionaler Tags müssten noch ermittelt werden. Darauf weist auch Meiert hin. Auch zu eruieren in der Verrechnung dessen, was durch Einfügungen durch die Browser von all dessen, was der Mensch im Quelltext weglässt, an Ressourcen von Seiten der Browser aufgebracht und verbraucht werden.
Diese Einsparungen an der HTML sind möglicherweise nicht nur unerheblich, sondern möglicherweise grundsätzlich auch dem Lesen und dem Verstehen von Quelltexten nicht förderlich.
Es hat schon einen befremdlichen Nebengeschmack, an der Lesbarkeit dieser Sprache „sparen“ zu wollen, für irgendeine konstruiert erscheinende „Performance“ und für eine spekulativ gedachte rascherer Datenübermittlung im Netz.
Sparpotenziale?
Sparen könnte der Mensch und seine Website vielleicht an Scripten, CSS, externes Nachladen von Inhalten, seien es Bilder, Filme oder Schriften?
Sparen könnte der Mensch und seine Website, wenn er nicht für die kleine „Homepage“ gleich ein mächtiges Content-Managment-System (CMS) bemüht, das so manches mit in den Datenfluss schreibt, was weder der Mensch noch seine Website braucht.
Wichtig erscheint mir hierbei, das die Option optional bleibt. Also nicht zu einem „Error“ im Validator wird, weil dieses Optionale nun „verboten“ gedacht und gemacht wurde.
Beispiel Sparpotenzial im Netz
Der Rechtsklick meiner Maus zeigt auf Websites verwendet folgende Funktionen.




Wird der Rechtsklick meiner Maus von Seiteninhabern im Netz unterdrückt, ist dies ein Eingriff in meine Arbeitsumgebung – und schaut derart aus:
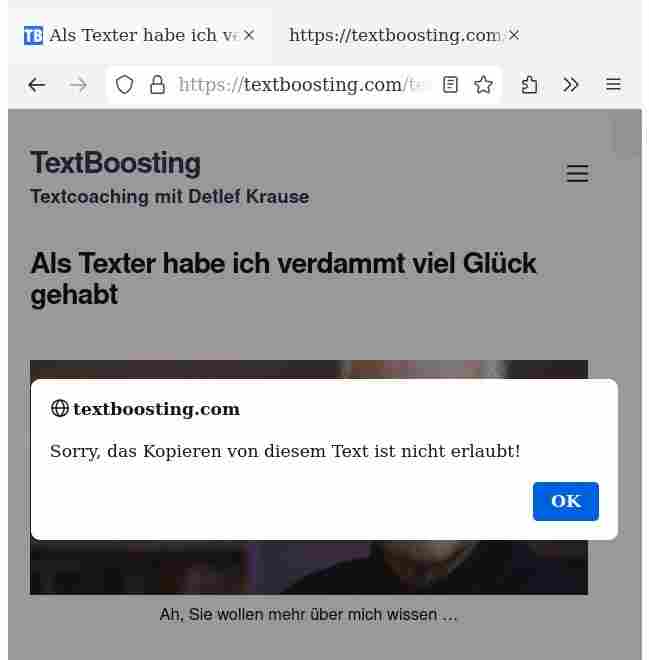
Klar, Ihr eigener Rechtsklick der Maus, Herr Seiteninhaber, ist (nur) fürs Kopieren …
Für solche Praktiken im Netz fehlt mir jeglicher Sinn.
Nebenbei, via Strg und U kopiere ich bei Bedarf Ihren Text – fertig formatiert aus Ihrem Quelltext, mit oder ohne End-Tags …
Unsinn in Variation [samt Quelle, wer es wünscht].
Beispiel SVG
Hier ist es nicht möglich, „verbotene / optionale“ Tags einsparen zu wollen: es funktioniert dann schlicht das Gewünschte nicht.
Überspringen
<svg viewBox="0 -80 1000 200" class="svg-regenbogen">
<defs>
<linearGradient id="verlauf">
<stop offset="0" stop-color="red"></stop>
<stop offset=".25" stop-color="orange"></stop>
<stop offset=".45" stop-color="yellow"></stop>
<stop offset=".65" stop-color="green"></stop>
<stop offset=".82" stop-color="blue"></stop>
<stop offset="1" stop-color="purple"></stop> </linearGradient>
</defs>
<text stroke="url(#verlauf)" x="0%" y="30%" style="fill: #000;">Option<tspan rotate="20">ale</tspan><tspan rotate="-20">T</tspan>ags</text>
</svg>
Überschriften (h1 bis h6) und <ul>, <ol>, <pre>, <code> (…) sind ebenfalls ausgenommen und erfordern ein End-Tag.
Quintessenz
An der wunderbaren HTML, die alleine das Netz bestücken könnte, sollte der Sparfuchs nicht allzu heftig knabbern.
Wer nach Möglichkeiten der Einsparungen von Datenflüssen und Volumen sucht, nach besserer „Performance“ und derlei, sollte möglicherweise an anderer Stelle beginnen – und ebenda Konsequenz zeigen:
Scripte raus, externes Nachladen von Inhalten reduzieren, externe Anbieter auf den eigenen Seiten reduzieren oder entfernen, CSS-Eskapaden unterlassen … und (ich darf weiter träumen) die Ressourcen ruhen lassen, die benötigt werden, um die Nutzer des Netzes auszuspionieren.
Nebenbei, dieses Spiel gewisser Theoretiker und Philosophen auf der Klaviatur der Profiliga der Webgestaltung wirkt mitunter leicht angestrengt, schlimmer aber sind nicht wenige Kasper der trendigen „professionellen Webdesign-Agenturen“: Für Euch und Euren Websites und Kunden-Websites ist das Netz nicht gedacht! Ihr habt nicht alleine die Leine zu führen, wohin die Reise via Trends
und Scripten
so geht.
Der offene, frei zugängliche, der reale Pragmatismus der Webgestaltung – einer schlichten Webgestaltung – habe am Ende Vorrang, wenn es der Vermittlung von Inhalten dient, Vorrang vor jeder Standardisierung und Validierung – und natürlich Vorrang vor dieses ignorante bis gruselige Theater aus den Häusern mancher Agenturen.
Der Zugang ins Netz ist für jeden offen zu halten, für alle Nutzer und alle Macher.
Sogar für Rosenbauer …
Das „Optimieren“ der eigenen Website ist kein Selbstzweck …
Redliche Bemühungen, mit den eigenen Seiten einen Nutzen für andere zu bieten, muss – so erscheint es mir – der Mensch im Netz schon suchen … und finden wollen?
Möglicherweise sind diverse Handhabungen von Quelltexten ein Indikator für diverse Motivationen der Webgestaltung.
Ein gutes Ziel:
Quelltexte – für alle gut lesbar, dienlich, brauchbar, samt allen derzeitigen Optionen, die diese Sprache HTML in sich trägt, also semantisch sinnvolle Quelltexte, welche über die eigenen Begehrlichkeiten hinaus für andere von Nutzen sind.
Mitunter erscheinen Bestrebungen für eine geforderte, irgendwie effizient und notwendig gedachte „Weiterentwicklung“ des WorldWideWeb nur als ein Zerren an der Leine.
Der Einsatz von Künstlicher Intelligenz im Web ist auch so ein Zerren (…)
Jede „Weiter-Entwicklung“ sei – diesem Wort folgend – löblich und gut. Aber das Grundlegende zu bewahren, notfalls wieder herzustellen, es sei besser: die Zugänglichkeit und Lesbarkeit von Quelltexten zum Beispiel … und dass das Netz von Menschen für Menschen gestaltet gehört.
Die kulturell-geistige Entwicklung des Menschen innerhalb des WorldWideWeb kann nicht ernsthaft das Ziel haben, Inhalte via klug gedachten Algorithmen und Scripten auszuliefern, um mit selbst genutzten, noch klüger gedachten Algorithmen und Scripten zu antworten … während zeitgleich Wege gesucht werden, html einzusparen … gepaart mit den doch unsäglich zu benennenden Tendenzen, Quelltexte bis zur Unlesbarkeit zu deformieren.